A side project of mine is a video-game price-comparison catalogue. It pulls product data from a handful of retailers — affiliate feeds, public web APIs, a couple of cookie-based scrapers — and shows you which of them currently has the best price on a given title. About 27,000 editions across ~12,000 games.
Each retailer hands me a cover image with its product data. Different retailers paint the same game very differently:
- One ships clean, flat scans of the box art.
- Another renders a 3D plastic-case mockup with their own publisher overlays.
- A third uses a flat-lay photo of the deluxe-edition contents (artbook, figure, steelbook open with the metal artwork showing) — pretty, but it doesn’t look like the SKU you’d buy.
- Several add console-logo banners or “available on PS5 / Switch / Xbox” badges across the top.
- One occasionally hot-links a placeholder image with “ART NOT FINAL” stamped on it.
When two retailers carry the same game, the catalogue picks one cover to show as the primary on the game’s detail page. Pick wrong and the page reads as cheap or confusing. So I needed a way to rank the available covers and surface the cleanest one.
That’s the problem the model below solves.
What “bad” looks like
After staring at a few hundred mismatched covers I settled on 14 quality classes that capture how a cover can go off:
| Label | What it means |
|---|---|
clean |
Standard front cover, photographed or scanned flat. The good one. |
3d_render |
Plastic-case mockup with the box rotated 3D, publisher renders. |
deluxe_bundle |
Cover shows the contents of the edition (figure, artbook, open steelbook) rather than the box. |
contents |
Similar to deluxe_bundle but for code-only / paper-insert reveals. |
wrong_console |
Right game, wrong platform’s SKU. |
wrong_game |
Scraper matched the wrong product entirely. |
low_resolution |
Tiny natural pixel size; text is barely readable. |
multi_platform |
“Available on: Switch / PS5 / Xbox” badge strip — usually a pre-order listing. |
gkc |
Game-Key Card (a digital-licence-in-a-box format). |
ciab |
Code-In-A-Box — the box just contains a download code, no physical media. |
placeholder |
“ART NOT FINAL” provisional cover. |
margins |
Excessive whitespace padding around the artwork. |
bad_background |
Non-white or transparent background, often “glitchy” or mixed white+black. |
unclear |
Fall-through bucket for the labeller. |
Ten of those labels are visible from the cover alone — one real example per label, pulled from the catalogue:
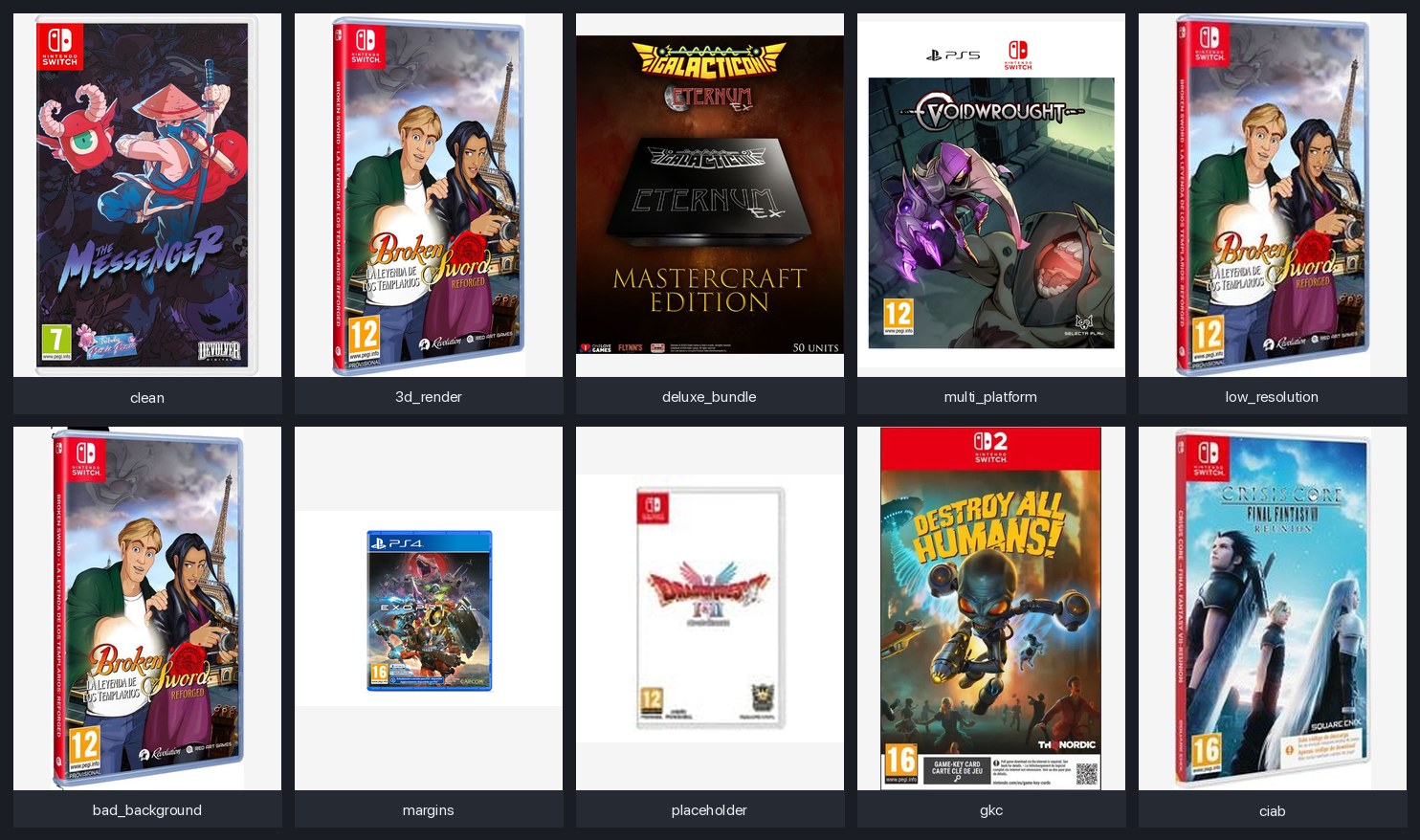
wrong_console and wrong_game aren’t in the grid because they’re not visible from the cover alone. A wrong_console cover often looks like a perfectly fine cover — the problem is that the retailer listed a PS5-styled mockup under their Switch SKU. A wrong_game cover often looks like a perfectly fine cover — the problem is the scraper matched a different title. Those labels need cross-context — what the cover looks like next to what the listing claims — and the model has to be fed that context explicitly. More on that in the architecture section.
Plus a separate 4-class platform head — nintendo / sony / xbox / pc — that I use as a sanity check against the retailer’s claimed platform. A cover that the model thinks is “obviously a PS5 box” but the retailer listed under switch2 gets demoted in the ranking, because it’s almost always a pre-order template that’s been mis-tagged.
Architecture: shared backbone, two heads, one of them multi-input
The catalogue runs on a 4 GB ARM cloud VM. Anything heavier than that has to fit alongside Gunicorn workers, an SQLite DB and a few cron-driven scrapers. So the model is deliberately tiny:
- Backbone (shared, frozen):
torchvision.models.mobilenet_v3_smallwith ImageNet weights. Strip the classifier head and a forward pass yields a 576-dim feature vector per cover. The backbone is never fine-tuned — it’s just a fixed feature extractor. - Quality head: a 14-class MLP with a 1,166-dim input, hidden layer 64, dropout 0.5, weight decay 1e-3. The input is a concatenation of four sources:
- 576-dim image feature vector (from the backbone)
- 4-dim declared-platform-family one-hot (the listing’s claim)
- 576-dim per-game prototype — mean of other editions’ image features for the same game, zeros if it’s the only one
- 10 hand-engineered scalars — per-side near-white ratios, per-corner background flags,
log10pixel count,log10Laplacian variance
- Platform head: a 4-class MLP,
576 → 64 → 4. Image features only — predicting the platform from the cover is the point, so adding declared-platform as input would defeat it.
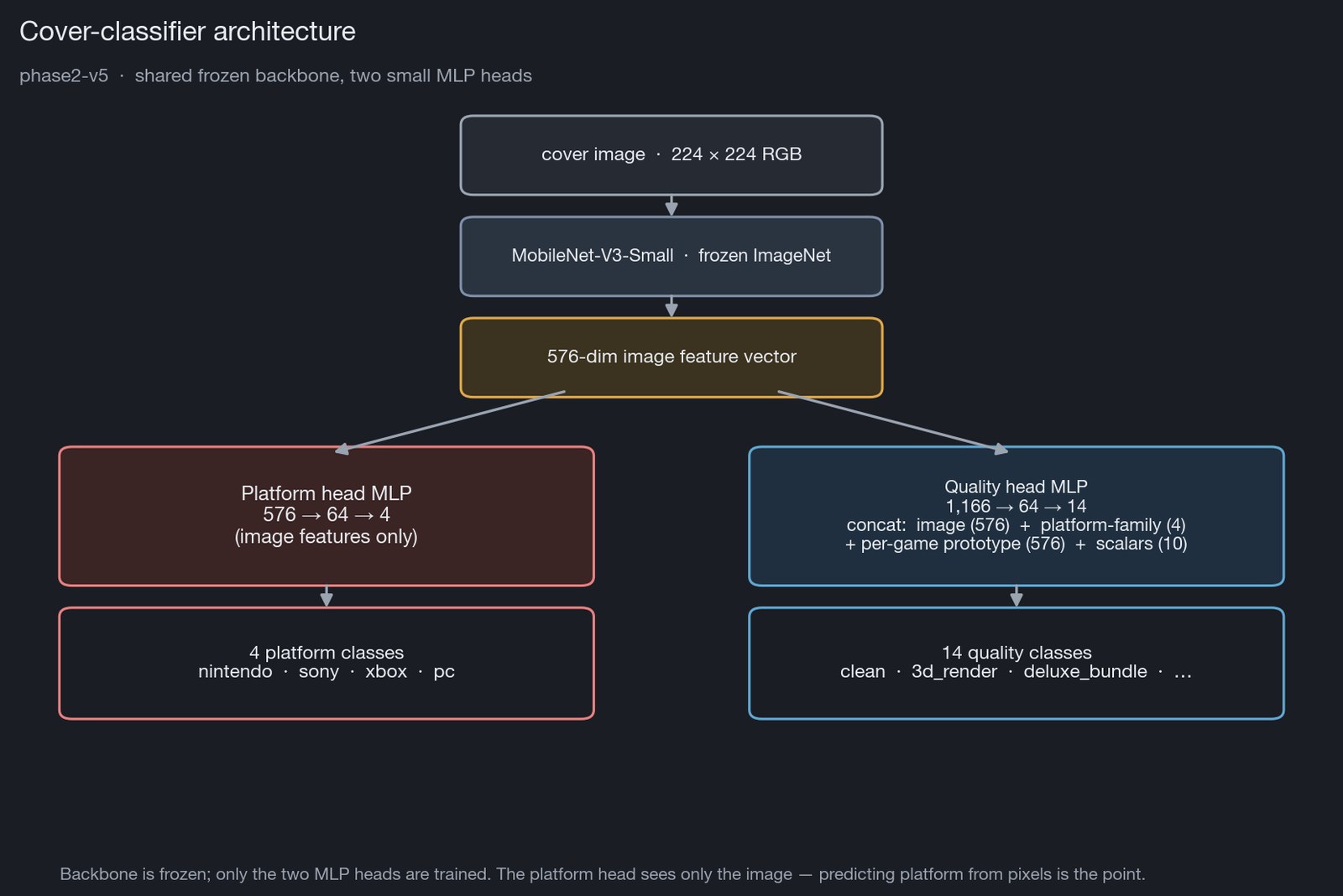
The heads are independent. An edition can carry both labels, only one (e.g. when the platform head’s confidence is below threshold the edition stays platform-unknown but its quality verdict still lands), or neither (if both heads abstain).
The quality head’s input grew over time. The first three versions used only image features — and got stuck at 0 % validation accuracy on wrong_console and wrong_game, because a cover image carries no information about the SKU’s declared platform or which game it belongs to. The model wasn’t capable of learning those classes from the pixels alone. Adding the platform one-hot (the listing’s claim) and the per-game prototype (what the other covers of the same game look like) was the unlock — and the 10 hand-engineered scalars on top fix labels like margins and bad_background that the 224×224 convnet can’t read directly at that resolution.
Features are extracted once per cover and cached to cover_features.npz. Training is just MLP-over-cached-features after that, which keeps the retrain loop fast — about 7 minutes warm cache, 15 minutes cold on the 4 GB box, with the training process throttled to 90 % of one CPU core via systemd-run --user --scope -p CPUQuota=90% so it doesn’t fight the web server for cycles:
nohup systemd-run --user --scope -p CPUQuota=90% \
env OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 \
taskset -c 0 nice -n 19 ionice -c 3 \
./venv/bin/python -u scripts/train_cover_cnn.py \
> /tmp/train.log 2>&1 &OMP_NUM_THREADS=1 + MKL_NUM_THREADS=1 keeps PyTorch’s thread pool from spinning up CPU-pinning workers that fight the CPU quota. taskset -c 0 glues the whole job to one core, nice -n 19 + ionice -c 3 make sure Gunicorn always pre-empts.
Training data, and why the LLM labels had to go
The catalogue has a CoverVerification table that stores one labelled row per cover per “classifier version”. Three label sources feed training, each overriding the previous:
- Reviews of earlier-version predictions. When an earlier model flagged a cover as
3d_renderordeluxe_bundleand a human confirmed or rejected it, that becomes a high-quality training row. - Direct multi-select labels. A staff-only
/admin/label/covers/page surfaces unverdicted covers and lets the labeller tag each with as many of the 13 classes as apply, subject to exclusivity rules (wrong_gameexcludes everything;cleanexcludes the BAD_LABELS set;gkcandciabare mutually exclusive; etc.). - Cover-picker pins. On the game-detail page, staff can tap a different edition’s cover to make it the primary. That tap writes a
manual-pin / cleanrow for the chosen cover andmanual-pin / unknownrows for the siblings (telling the ranking they were not chosen).
For a while I also let a small LLM label borderline cases — feed it the cover image, ask “is this a 3D render, a deluxe bundle, or a clean cover?”, and merge the answer into the training set. That was a tarpit. The model would confidently hallucinate 3d_render for actually-clean low-resolution covers, and clean for slightly stylised renders. The signal-to-noise ratio was bad enough that the LLM-labelled rows visibly degraded validation accuracy. I removed the entire source. Training is now human-verified labels only.
The lesson, stated cleanly: vision-language models are not free labels. When the labelling task has structure (well-defined classes, exclusivity rules, edge cases that need a humans-in-the-loop convention), an LLM with no exposure to your conventions will make up something plausible-sounding rather than tell you the cover is borderline.
Class imbalance nearly killed it
The first attempt at training was a quiet disaster.
I had ~4,000 covers auto-flagged low_resolution by a simple-rule script and only ~800 hand-labelled clean. With no class weighting and no per-class cap, the model learned to predict low_resolution for everything — clean-class accuracy collapsed from 87 % on the four-class predecessor to 0 %.
Two fixes, applied together:
- A hard per-class cap of 1,000 rows. Even when a class has many more available labels, training only samples up to the cap.
sqrt-inverse-frequency class weights, capped at 5×.
With both in place the model produced sensible per-class accuracies on a held-out set — clean 90 %, 3d_render 69 %, deluxe_bundle 47 %, margins 45 %. The tail classes (gkc 20 %, ciab 0 %, wrong_console 0 %) still look bad, but those val splits are 5–10 examples wide; the right fix there is more labels, not architectural changes.
How inference decides what to do
The catalogue runs the model in two modes:
- Full sweep:
verify_cover_cnn.py --apply --rescan-allpredicts every edition. ~45–65 minutes on the 4 GB box, ~7 covers/sec. - Targeted sweep:
--rescan-verdicts 3d_render,deluxe_bundle,unknown,…only re-predicts editions whose previous verdict is in the supplied set. Typical after a retrain — skip the 15 000-rowcleanblock and rescore the ~12 000 non-clean editions. Cuts a sweep to ~40 minutes.
For each cover the quality head’s argmax is taken, then a confidence floor is applied:
CLEAN_THRESHOLD = 0.35 # lower than the old 4-class scheme — see below
def quality_from_probs(probs):
idx = probs.argmax()
if LABEL_CLASSES[idx] == "clean" and probs[idx] < CLEAN_THRESHOLD:
return "unknown"
return LABEL_CLASSES[idx]The threshold’s existence (and that specific value) deserves a comment. The previous-generation model had four output classes (clean / 3d_render / bundle / unknown) and used CLEAN_THRESHOLD = 0.55. After expanding to 13 classes, probability mass spreads thinner — a perfectly confident clean cover might only put 0.42 on the clean class because there are 12 other places for the rest of the softmax to land. Keeping 0.55 would have rejected most of the clean predictions and over-flagged. I lowered to 0.35 after eyeballing the score distribution on a confirmed-clean test set.
The platform head uses a more conservative PLATFORM_THRESHOLD = 0.70. A wrong platform label is more dangerous than a wrong quality label — it demotes the cover in ranking even when the cover itself is fine — so the head is asked to abstain (unknown) unless it’s quite sure.
From label to cover-on-the-page
The classifier output is one signal among several. The actual primary-cover decision lives in a database Subquery that ranks every edition’s cover and picks the best (lower number wins):
| Tier | Labels |
|---|---|
| 0 | clean, gkc, ciab (the last two are product attributes, not cover quality — they describe the SKU, not the image) |
| 1 | 3d_render |
| 2 | low_resolution, deluxe_bundle |
| 3 | margins |
| 4 | unknown / unclear / no verdict yet |
| 5 | contents |
| 6 | multi_platform, wrong_console, wrong_game, placeholder |
Within a tier, a shop-preference list (which retailers historically ship the cleanest covers) is the tie-breaker. Manual pins always win over classifier output — staff judgement always trumps automation.
One subtle bug bit me here for weeks. The manual-pin / unknown rows the cover-picker writes for siblings of a manually-picked cover were being read by the ranking as a verdict, demoting those siblings to tier 4 even when the same edition had a perfectly good phase2-v4 / clean row from the CNN. The fix was to exclude manual-pin rows with verdict unknown from the “latest verdict” calculation — they’re demotion markers, not real classifications.
Active learning, kept simple
There’s no continual-learning loop. Retraining is reactive: when a new retailer joins the catalogue, when a new mockup style starts showing up, or when a labelling session has added enough new rows that another epoch over the data would actually help.
The labelling UI is the heart of the loop. Default mode pulls editions in priority order:
- Tier A — editions where the model returned
unknown(lowest confidence, highest expected information gain from a label). - Tier B — rare classes with fewer than 100 manual labels (computed live per request).
- Tier C —
3d_render/deluxe_bundle/marginsboundary cases. - Well-supported classes (
cleanand friends) are skipped.
This keeps each labelling session pointing at where the model actually needs help, instead of asking me to confirm hundreds of obviously-clean covers.
Gotchas, from one through twelve
Some of these cost a session of debugging, some cost a week. Roughly grouped:
- Training-data hygiene — #1 feature cache, #2 class-name typo, #3 class imbalance, #4 the skip button, #5 demotion markers, #6 the missing label
- Inference & calibration — #7 confidence threshold, #8 unlearnable labels, #9 spatial features
- Production plumbing — #10 keep the old heuristic, #11 timer early-exit, #12 CPU contention
In rough order of how much they hurt:
1. The feature cache holds labels too
The .npz file caches both the 576-dim image features and the label vectors the features were extracted with. If you retrain after re-labelling without deleting the cache, the resume-from-cache logic happily mixes the new features with the old labels, and you train on stale supervision. The model “doesn’t seem to be learning” — but actually it’s learning the right thing on the wrong target. I lost a week to this before noticing. Standard pre-retrain step now: rm data/cover_features.npz.
2. A class-name typo silently demoted predictions for weeks
An internal helper used "bundle", the LABEL_CLASSES list used "deluxe_bundle", and the inference code mapped string-by-string through a hard-coded {clean, 3d_render, bundle, unknown} set inherited from the previous-generation model. Every confident deluxe_bundle prediction missed the string compare and was mapped to unknown. The inference logs looked fine; the catalogue just never produced a single deluxe_bundle row. Fixed by passing argmax through verbatim for all 14 classes — no string mapping, no inherited four-class allowlist.
3. Class imbalance turned the model into a one-trick pony
The first real training run was a quiet disaster. A bulk auto-flag script had produced ~4,000 low_resolution rows; the hand-labelled clean set was ~800. With no class weighting and no cap, the model converged on “predict low_resolution for everything” and clean-class accuracy collapsed from 87 % on the four-class predecessor to 0 %. The fix was two-part, applied together: a hard per-class cap of 1,000 rows before training even starts, and sqrt-inverse-frequency class weights capped at 5×. The cap stops dominant classes drowning out rare ones; the cap on the weights stops a rare class with one example from getting an 83× weight that destabilises the loss surface.
4. The skip button used to write rows
An early version of the labelling UI recorded a manual-train-unclear row whenever the labeller hit Skip, so the edition would drop out of the queue. That row then poisoned two things at once: – Training: the loader treated it as a labelled unclear example and the model learned to predict unclear on borderline covers. – Ranking: unclear is tier 4 by default — so a previously-pinned-clean edition that the labeller passed on would silently lose its tier 0 status and demote.
252 spurious rows had to be deleted from the database. Skip now writes nothing; the skipped edition_id is tracked in session state (skipped_in_session, capped at 500) and filtered out of the rest of the session’s queue.
5. Demotion markers broke their own ranking
The cover-picker writes two kinds of rows when staff manually picks an edition’s cover as the primary: manual-pin / clean on the chosen edition, and manual-pin / unknown on each sibling edition (so the picked cover always wins, regardless of which retailer the sibling came from). The ranking Subquery initially treated those manual-pin / unknown rows as real manual verdicts, demoting siblings to tier 4 (default) even when their own CNN verdict was clean. The pinned cover did win — but for the wrong reason, and the moment a new clean classifier verdict came in for a sibling, the ranking went haywire.
The fix is one line in the latest-verdict Subquery: exclude manual-pin rows with quality_verdict='unknown' from the “what’s the most recent manual signal” lookup. They’re demotion markers, not real classifications.
6. A new label that wasn’t in LABEL_CLASSES got silently filtered
I added bad_background as the 14th class — created the manual-train rows, added it to the labelling UI’s button list, deployed. The next retrain quietly dropped all 29 manual-train-bad_background rows because the dataset loader filtered them out: the verdict string wasn’t in LABEL_CLASSES, so it wasn’t a known target. Took two retrain cycles before I noticed bad_background wasn’t moving off 0 % accuracy. The fix is trivial (append to LABEL_CLASSES; keep the index stable for old checkpoints), but now I lint LABEL_CLASSES against the DB’s distinct quality_verdict values at the top of every training run.
7. The clean-confidence threshold needed to track the number of classes
The previous-generation model had 4 output classes (clean / 3d_render / bundle / unknown) and used CLEAN_THRESHOLD = 0.55. After expanding to 13 (then 14) classes, probability mass spreads thinner — a perfectly confident clean cover often only puts ~0.42 on the clean index because the softmax has 12 other places for the remaining mass to land. Keeping 0.55 rejected most of the model’s actually-correct clean predictions and remapped them to unknown, which then over-flagged the catalogue for review.
I lowered to 0.35 after eyeballing the argmax-probability distribution on a hand-confirmed test set. There’s nothing principled about the specific number — it’s tuned to the n-class softmax actually in use. The platform head’s PLATFORM_THRESHOLD stays at a more conservative 0.70 because a wrong platform label is more dangerous than a wrong quality label (it demotes the cover in ranking).
8. Some labels are unlearnable from the image alone
Phase-2-v3 had wrong_console and wrong_game accuracies pinned at 0 %. The model wasn’t broken — the labels were unlearnable from the input it was given. A cover image carries no information about which platform the retailer listed it under, and no information about which catalogue game it belongs to. The model literally cannot tell you “this cover is for the right title but the wrong platform’s SKU” because both pieces of context are external.
The fix is the multi-input quality head described in the architecture section: the image features (576) get concatenated with a 4-dim declared-platform-family one-hot (so the model can compare what it visually sees against what the listing claims) and a 576-dim per-game prototype (the mean of every other labelled edition’s image features for the same game — gives the model “what this game’s covers usually look like” as reference). The plumbing took an afternoon and immediately moved wrong_game off the zero floor; wrong_console is in place but blocked on label volume rather than architecture now.
9. The convnet can’t see the diagnostic regions you can
margins, bad_background, and low_resolution are all about where specific pixels are — white padding on the outside, transparent or non-white at the corners, very small natural image size. A frozen MobileNet-V3-Small at 224×224 doesn’t have any path to learn “look at the outer 5 % of the image”. The model can guess from texture cues, but it’s slow to converge and the val accuracy stayed in single digits for those classes.
The pragmatic fix is to stop asking the convnet to do work that’s trivial to compute directly. The v5 head input includes 10 hand-engineered scalars:
- 4 × per-side near-white-or-transparent ratio (for
margins) - 4 × per-corner background flag (for
bad_background) log10(natural pixel count)(forlow_resolution)log10(Laplacian variance)(forlow_resolutionblurriness)
All computed on a 96-px nearest-neighbour resample so the cost is independent of source resolution. The module that computes them (games/cover_scalars.py) is shared between training and inference, so the head’s input vector is bit-identical between the two paths. There’s no clever trick — the convnet does what convnets do, and image-statistics features do what they do.
10. The old heuristic detector still beats the CNN sometimes
Before any of this, there was a phase-1 detector that did corner-colour sampling, top-band detection, and aspect-ratio gates. Pure heuristics, no model. It’s older and less general, but on certain wrong_console covers (specifically the ones that paint a coloured console-logo band across the top), the corner-and-band check is more reliable than the CNN’s per-image inference. The temptation when you ship the CNN is to delete the old code; the right move is to keep both in the mismatch-detection chain.
The catalogue’s platform-mismatch logic now reads “is there ANY classifier version (phase-1 or phase-2) that confidently says this cover’s platform disagrees with the listing’s claimed platform?” The CNN abstaining isn’t silence to fill with stale phase-1 data — but phase-1 confidently asserting something is real signal when the CNN is unsure.
11. The auto-classify timer has to early-exit hard
There’s a systemd timer that re-runs the classifier every 5 minutes against the catalogue, so any freshly-imported cover (from a feed sync, a Chrome-extension price ingest, or an admin upload) gets a label within minutes. Importing PyTorch + loading MobileNet + the trained head takes ~5 seconds and ~150 MB of RAM. Most ticks have zero pending covers.
The fix is an early-exit before any of that work: open SQLite, count editions that don’t have a row at the active classifier version, and if the count is zero, sys.exit() immediately. Idle ticks now cost ~100 ms and don’t fight Gunicorn for memory.
Related: the timer unit uses OnCalendar=*:0/5 (cron-style, fires on absolute time) rather than OnUnitActiveSec= (fires at fixed intervals from the last successful run). The latter style silently misses its window on long-uptime hosts where the service has been restarted recently.
12. Training on a small VM means fighting yourself for CPU
A retrain that doesn’t throttle locks up the web server for several minutes. The civilised launch is:
nohup systemd-run --user --scope -p CPUQuota=90% \
env OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 \
taskset -c 0 nice -n 19 ionice -c 3 \
./venv/bin/python -u scripts/train_cover_cnn.py \
> /tmp/train.log 2>&1 &The OMP_NUM_THREADS=1 / MKL_NUM_THREADS=1 pair is what stopped a “but I set CPUQuota=90%” bug — PyTorch’s BLAS will helpfully spin up one worker per core and saturate the CPU within the quota, choking Gunicorn anyway. Capping the thread pool at one means the quota actually does what it says. taskset -c 0 glues everything to a single core; nice 19 + ionice -c 3 make sure interactive traffic always pre-empts.
Where it stands
Five iterations in (phase2-v1 → v5), the catalogue-wide distribution looks like this:
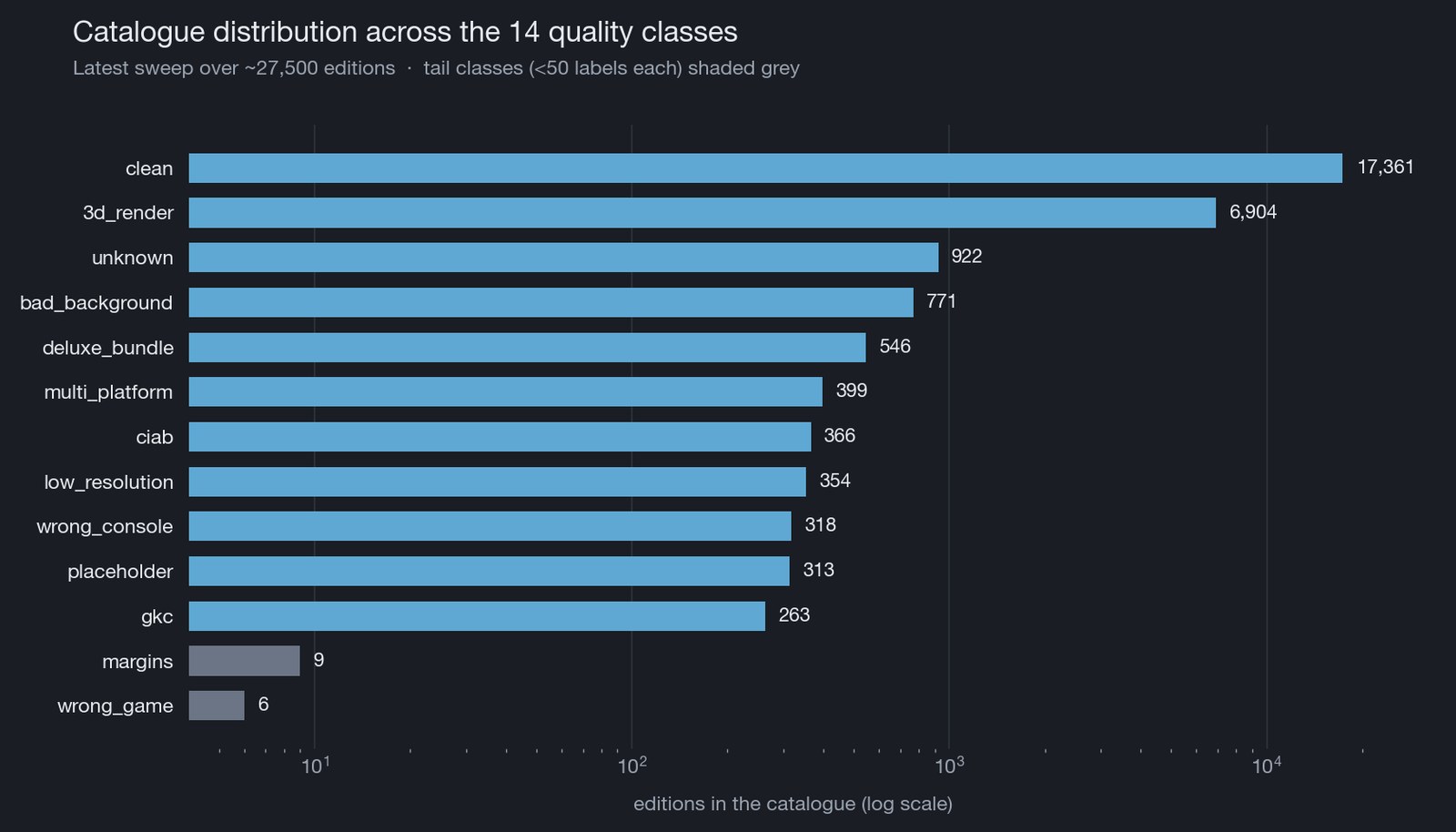
About two thirds of the catalogue is clean and almost all of the rest is 3d_render. Everything else — the tail this whole post is really about — is a few percent each, and those are exactly the editions where the cover-picker would otherwise surface something embarrassing.
The detailed phase2-v5 breakdown of the non-clean editions (clean rows are skipped on retrain since the model rarely flips them):
| Verdict | Count | Share of non-clean |
|---|---|---|
3d_render |
6,904 | 68 % |
unknown |
922 | 9 % |
bad_background |
771 | 8 % |
deluxe_bundle |
546 | 5 % |
multi_platform |
399 | 4 % |
ciab |
366 | 4 % |
low_resolution |
354 | 3 % |
wrong_console |
318 | 3 % |
placeholder |
313 | 3 % |
gkc |
263 | 3 % |
margins |
9 | <1 % |
wrong_game |
6 | <1 % |
Validation accuracy
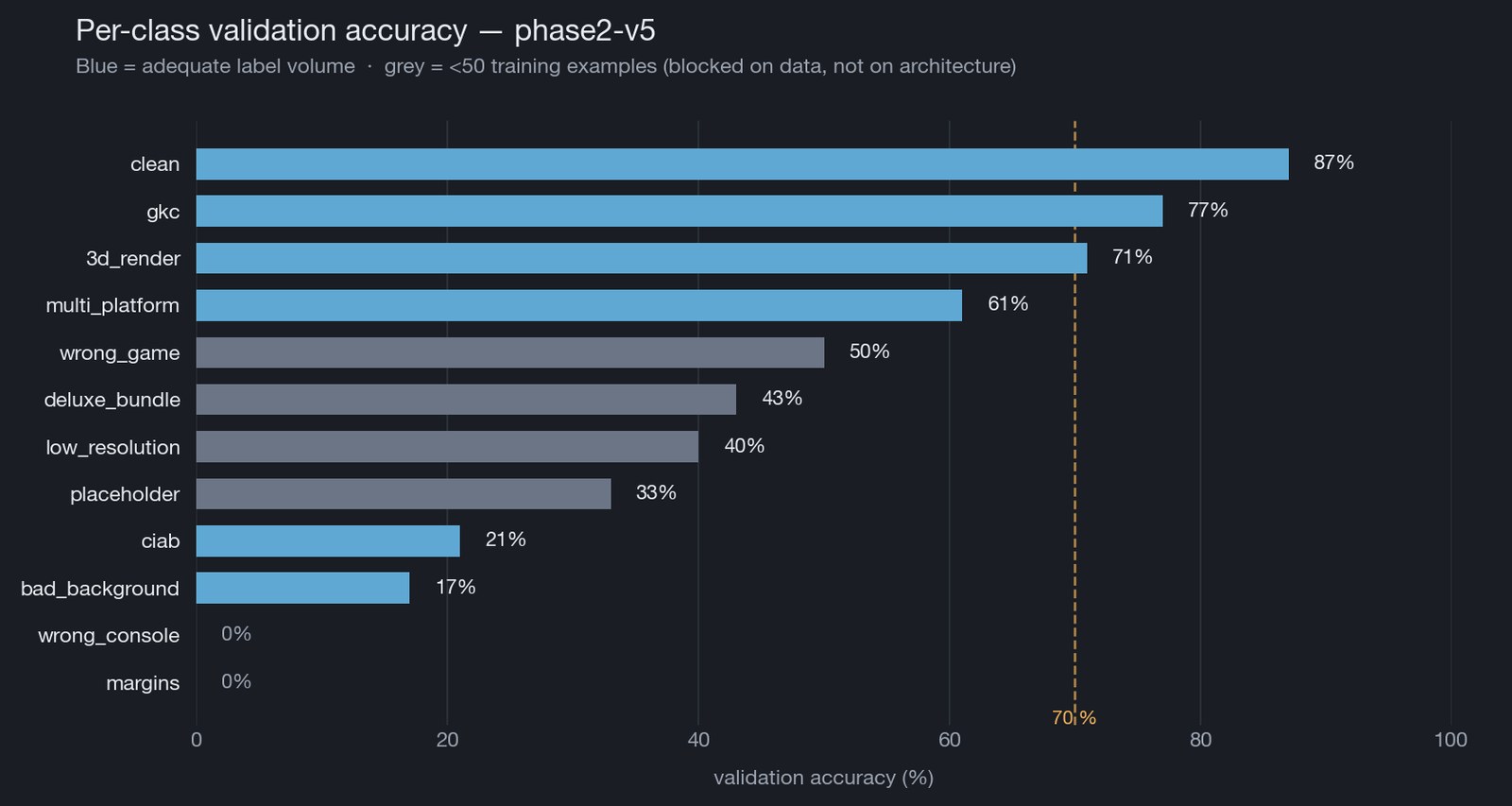
The five blue bars at the top are classes with adequate label volume — clean, gkc, 3d_render, multi_platform, wrong_game. The seven grey bars below all have fewer than 50 training examples; they’re blocked on data, not on the model. The right thirty-minute investment for moving those numbers up isn’t another architectural sweep — it’s another labelling session against the active-learning queue.
What’s next
A small training-data hygiene pass: a lint that catches when a manual label contradicts an existing CNN verdict, surfaces it for review, and reconciles before the next retrain. Together with the steady drip of labels from the active-learning queue, that’s what’ll move the rare-class accuracies.
Until then: a model small enough to retrain over a coffee, a labelling UI that knows what to ask me, and a ranking that quietly does its job in the background.