Last year I went to the Google Cloud Summit with a few colleagues. We saw a lot of impressive projects built around agents and LLMs, and walked out a bit deflated. As a data team — analysts, engineers, but not “pure” software developers — we could see the value clearly, but we’d seen this movie before: the moment we wanted to build something real, we’d be queuing up for backend developer time, or pricing out an external consultant to implement agents for us. Same bottleneck as always, just with a fancier label.
A year later, that bottleneck has quietly dissolved. We built it all ourselves — fast — with Claude Code as the agent in our IDEs. The projects we thought we’d have to outsource, we shipped on quiet afternoons.
And it isn’t just the work-shaped projects. I’m finally shipping ideas that have sat in my personal backlog for literally ten years — the kind of thing where every time you open the notebook you remember why you closed it last time. Now they’re real, deployed, and — the part I keep being surprised by — they’re solid. Tests, sensible error handling, security defaults that hold up to scrutiny. Not vibey demos. Things I’d hand to a friend without a list of caveats.
When people ask how much faster I work with the agent, my honest answer is that “faster” is the wrong axis. I built this chart for an internal talk last week to explain why.
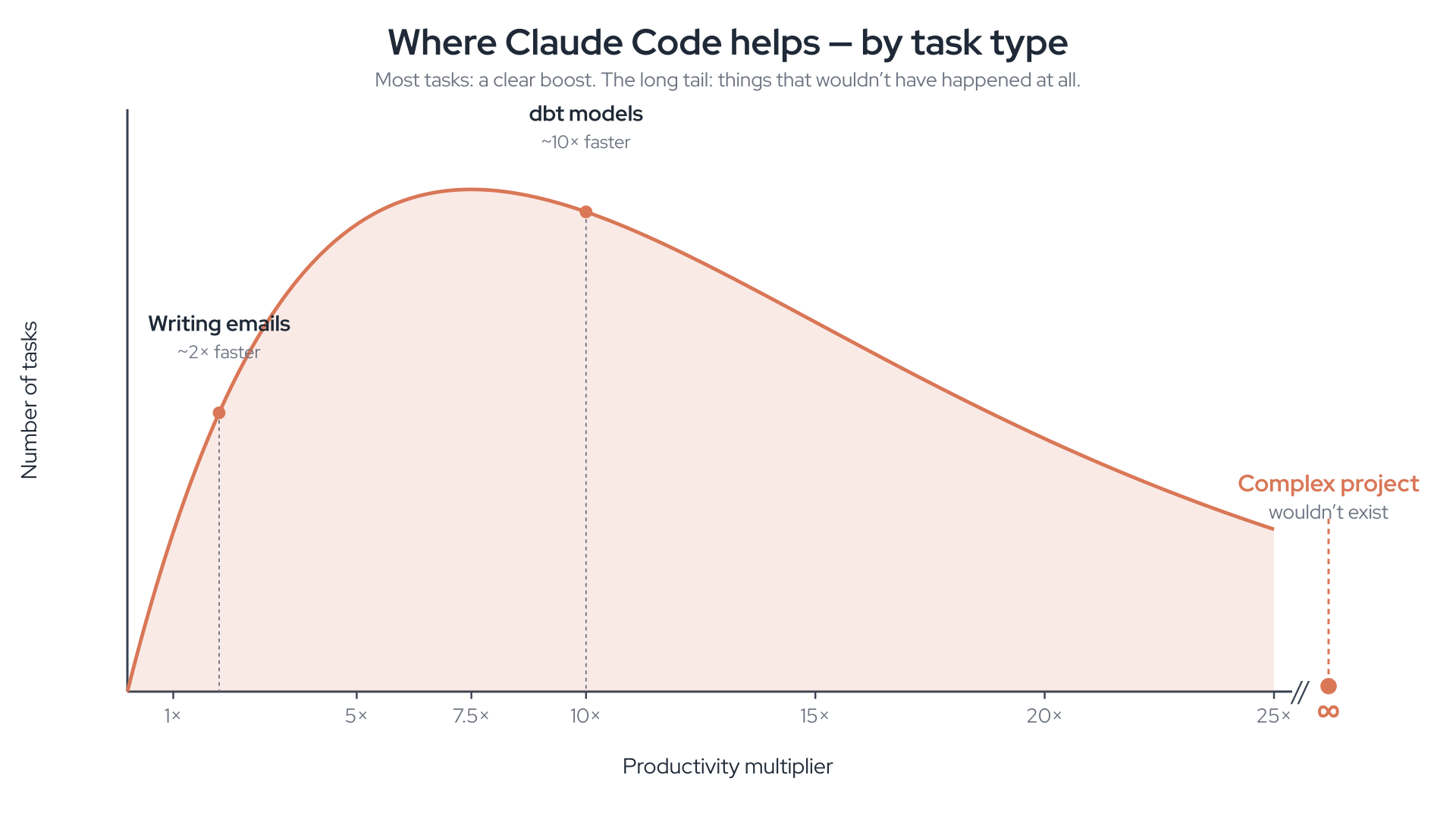
X-axis: productivity multiplier on the first try — how much faster a task is with the agent than without. Y-axis: number of tasks. Three points are pinned on the curve:
- Writing emails — ~2x faster. The agent helps a little, but I still write half the words and read all of them.
- dbt models — ~10x faster. Schema-heavy, repetitive transformation work. A model that used to take an afternoon takes twenty minutes.
- Complex side project — infinity. A Slack bot I built recently — with dashboard introspection, screenshot delivery, retry logic, secret rotation, the works — would simply not exist if I had to type it out on weekends.
The chart’s subtitle does the heavy lifting: most tasks: a clear boost. The long tail: things that wouldn’t have happened at all.
What’s actually in the tail
A few categories of work I now reach for that I’d have walked past a year ago:
- Solo end-to-end products in a few evenings. A fuel-price PWA with route planning, push notifications, a vehicle picker and LEZ overlays — a few weekends. A paper-trading bot on a Raspberry Pi with dual-wallet logic, trailing limits, broker API integration and over a hundred unit tests — another few. As a solo dev with a day job, neither would have made it past the “open a folder” stage without an agent absorbing the activation energy.
- Closing the loop on flows that used to need a human in the middle. So much internal automation is “90% there, with one manual step nobody has time to remove.” Removing that step used to mean reading three docs, gluing four APIs and handling ten edge cases for what amounted to a chore. Now the loop just closes.
- Using the whole cloud toolkit, not just the comfortable bits. Cloud Scheduler triggering Cloud Run jobs that read from GCS, call the Anthropic API, write results back to BigQuery — that’s a sentence I would have read with mild dread last year. Now it’s a Tuesday afternoon. The fluency tax on each individual GCP service has dropped to roughly zero.
- Recurrent analysis that doesn’t fit a static dashboard. Product A/B tests are the cleanest example. Each test has different success criteria, different segments, different pitfalls. A dashboard can show metrics; it can’t tell you which test is meaningful and why. Letting an agent read the experiment spec and the metrics and write the analysis is genuinely better than the static report I would have built before — because the static report would always be wrong for the test that doesn’t fit the template.
Why “X faster” breaks down
A productivity multiplier is bounded by the time you would have spent. If a task would have taken an hour and now takes ten minutes, that’s 6x. If it would have taken a day and now takes an hour, that’s 8x. The number stays in a tidy range and you can put it on a slide.
But what’s the multiplier for a project you wouldn’t have started? The denominator is zero, or close enough. Any non-trivial side project competes with sleep, family, and the version of yourself who would rather watch a film. The activation energy alone — bootstrapping the repo, choosing a framework, setting up auth, deploying, debugging the first deploy failure — is usually higher than the energy you have on a Tuesday evening.
An agent doesn’t speed up activation energy. It absorbs it. That’s not a 25x; it’s a category change.
Why the framing matters
If you only see the peak of the curve, the question is which existing tasks should I delegate? Useful, but limited. It treats the agent as a faster version of what you already do.
If you see the tail, the question becomes what work was I never going to do that I should now consider doing? That shifts what I bring to the agent. I’m more willing to start things. I’m more willing to throw a half-formed idea at it on a Sunday morning and see if a working version of itself comes back two hours later. The cost of “trying” has collapsed.
The multiplier on existing work is nice. The work that now exists at all is the part I’d defend to a sceptic.